Model 1: Baseline YOLOv8
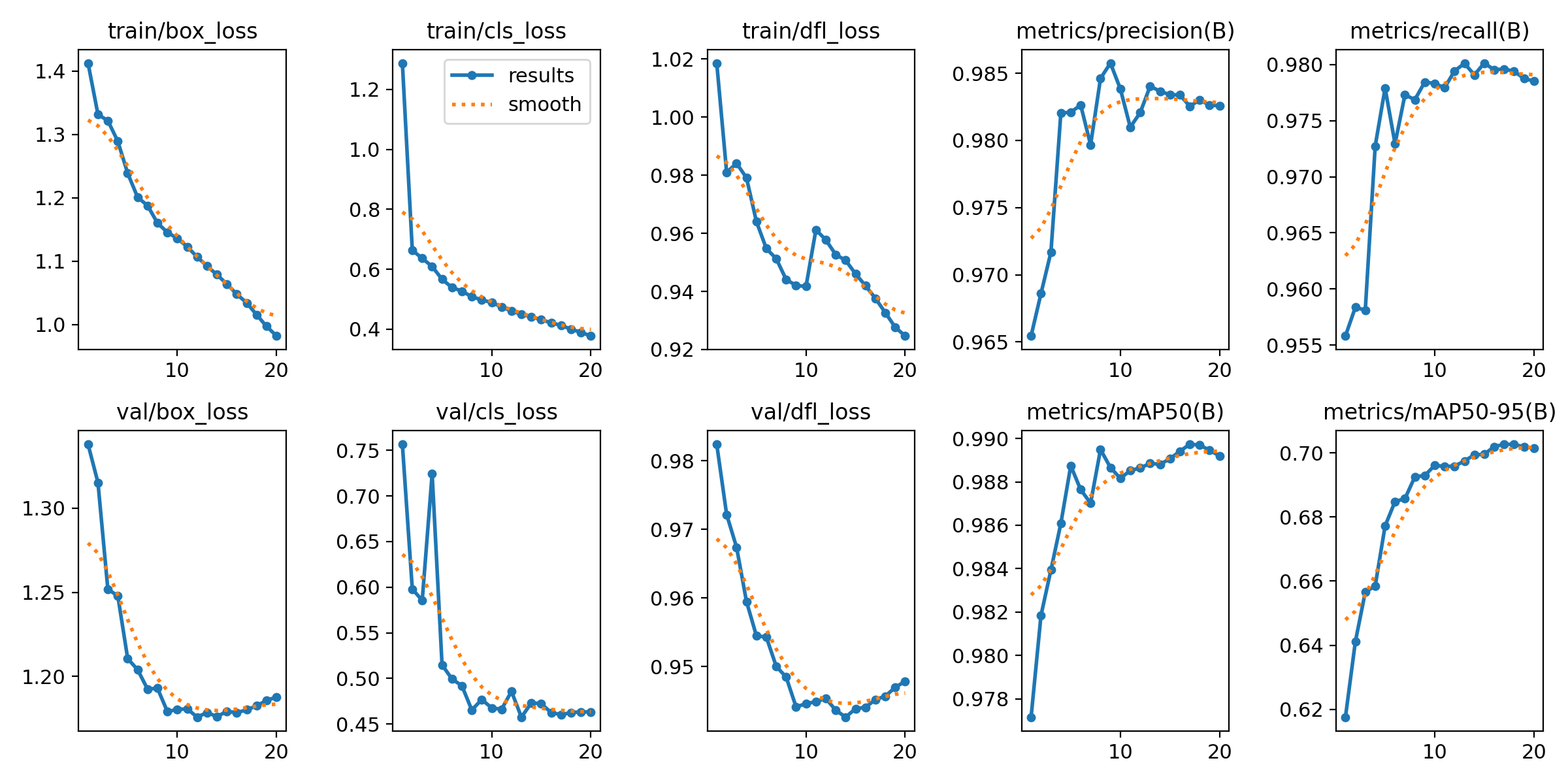
Model 1 represents the initial implementation without additional augmentations, trained exclusively on the original Anti-UAV dataset. The training curves show stable training with gradual loss reduction and high accuracy from early epochs. The model achieves mAP@50 of approximately 0.98 and mAP@50-95 of 0.68-0.70, indicating good adaptation to test data.
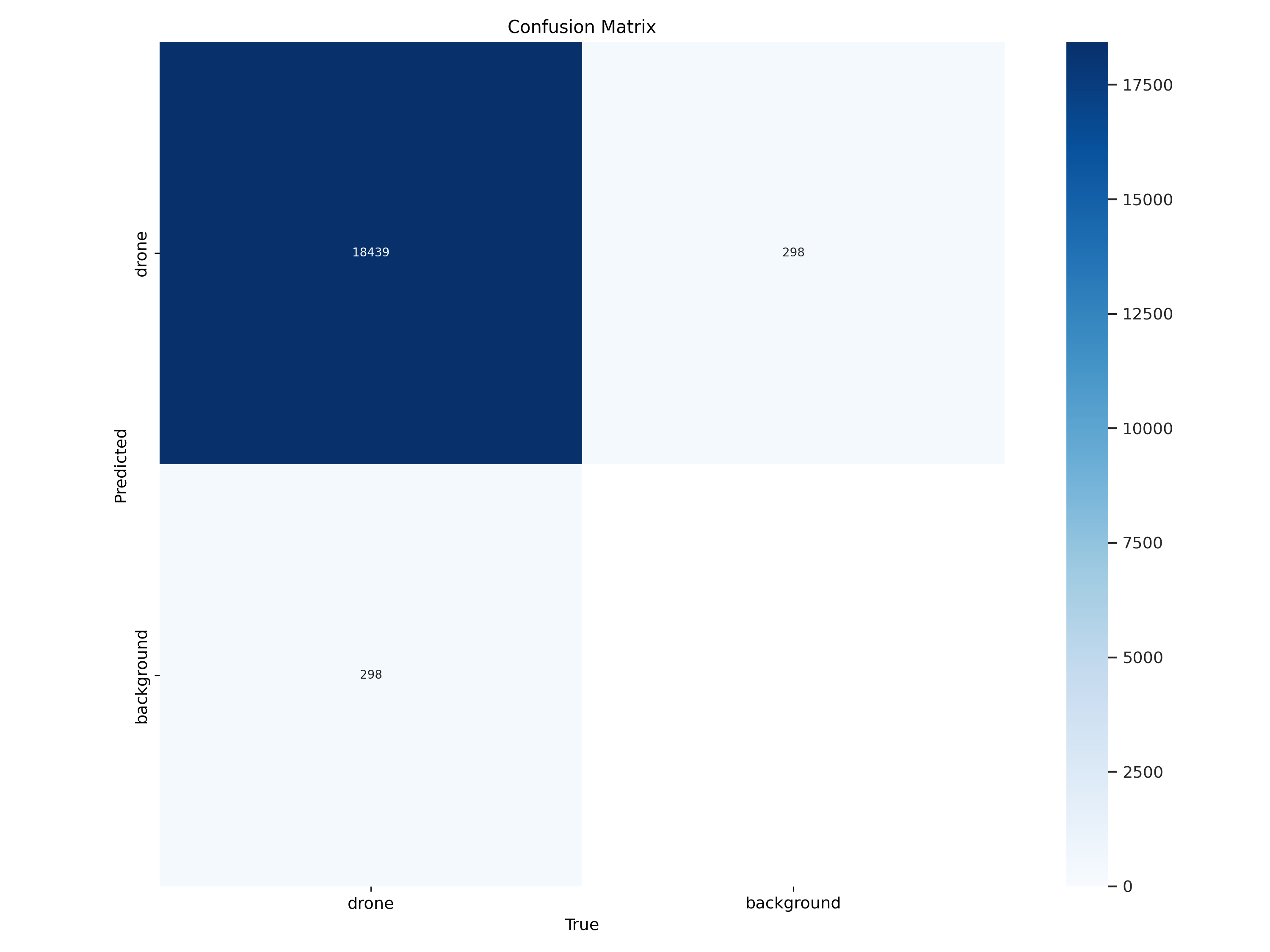
The confusion matrix shows high accuracy for drone detection with around 18,400 correct predictions. However, there is a small percentage of false positives where the model marks background as drones. This baseline establishes solid performance for cloudy, long-distance scenarios.
Key Metrics: Precision 0.97, Recall 0.975, mAP@50 0.98, mAP@50-95 0.68
Model 2: Vertical Flip Augmentation
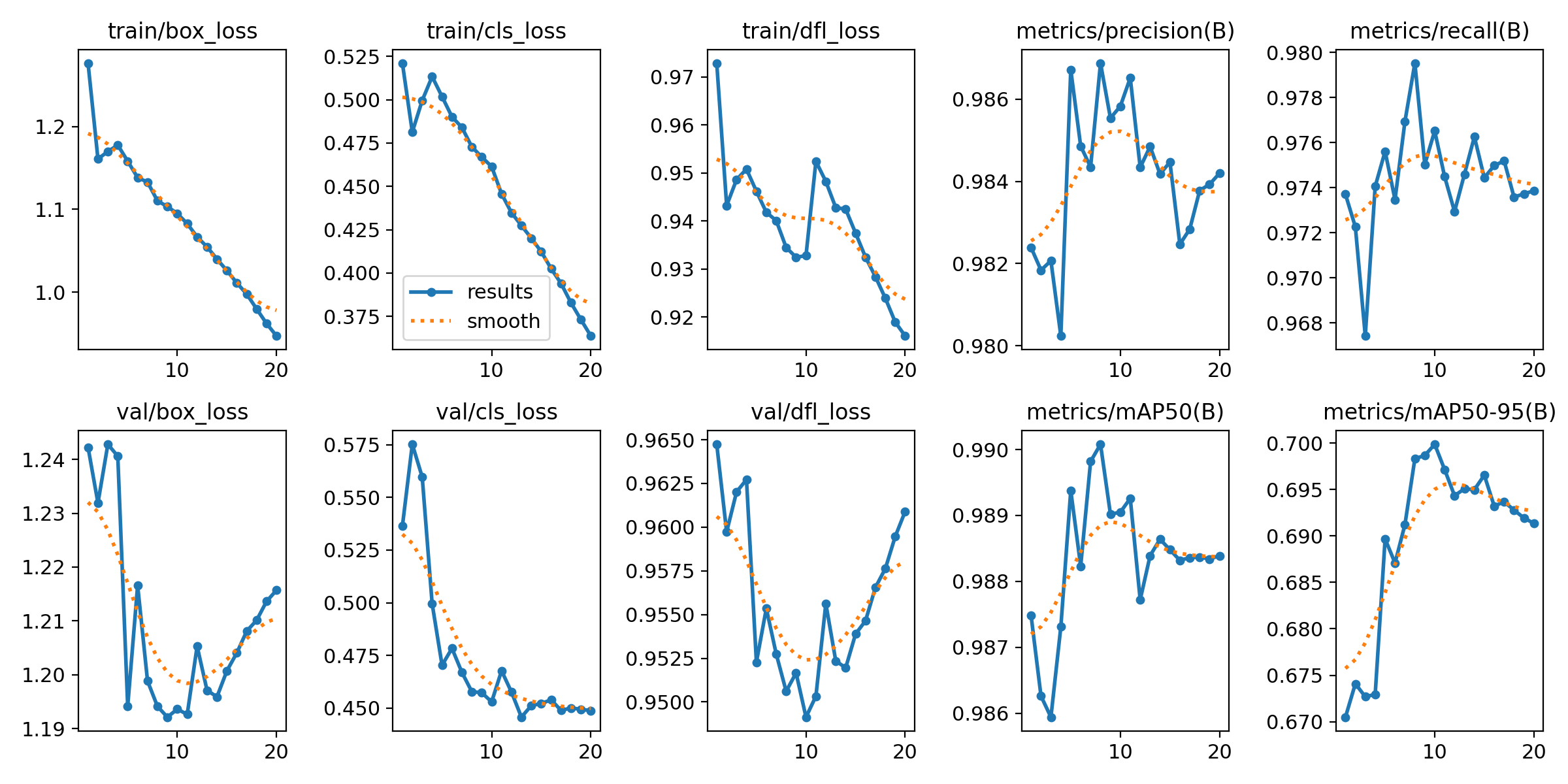
In an attempt to improve performance, Model 2 was trained with additional vertical augmentation, which should help with images showing various drone perspectives. Results show slight improvement in precision (0.976) and recall (0.978). mAP@50 reaches 0.99 in some cases, and mAP@50-95 moves toward 0.69.
This means vertical flipping has a positive but limited effect on detection accuracy. The main conclusion is that this augmentation helps for certain viewing angles but doesn't cause dramatic improvements. The benefit is measurable but modest, suggesting that vertical perspective variations were already somewhat represented in the original dataset.
Key Metrics: Precision 0.976, Recall 0.978, mAP@50 0.98-0.99, mAP@50-95 0.69
Model 3: Horizontal Flip Challenges
Model 3 was trained with horizontally flipped images, but results show this is not the best approach. Although losses continue to decrease, detection confidence significantly drops. Some detections have much lower confidence (50-60%) compared to previous models which maintain confidence of 76-78%.
This can be attributed to the fact that the data doesn't contain enough scenarios where drones are viewed from opposite horizontal orientations. Such training might actually confuse the model rather than help it generalize better. This finding highlights that not all augmentations are beneficial—transformations that don't reflect real-world variations can harm performance.
Key Metrics: Precision 0.95, Recall 0.94, mAP@50 0.93-0.95, mAP@50-95 0.62
Model 4: VisioDECT Integration
The most interesting result comes from Model 4, which was trained with the VisioDECT dataset for the first time. By including this dataset, the model became much better at detecting drones in various scenarios, especially in close and high-resolution images. Precision and recall remain around 0.99, while mAP@50-95 reaches 0.70, making it the best model in this research.
This shows that including different scenarios in training significantly improves the model's ability to generalize. The VisioDECT dataset's diversity in lighting conditions, distances, and resolutions provided the model with richer training examples, enabling better performance across a wider range of conditions.
Key Metrics: Precision 0.99, Recall 0.99, mAP@50 0.99-1.00, mAP@50-95 0.70+
Comparative Analysis
Model 4 is the best choice for real-world application due to its superior generalization, but Models 1 and 2 are also good for specific conditions. Model 3 showed limited effectiveness and is likely the least useful in this situation. The results demonstrate that dataset diversity matters more than simple geometric augmentations for improving drone detection performance.